Explore projects
-
ESB / ensemble_spieceasi
GNU General Public License v3.0 onlyNetwork Analyses - SpiecEasi The Rscripts and Snakefile herein can be used to run SpiecEasi for generating networks from taxonomic counts Dependencies snakemake >= 5.3.0 References (SpiecEasi)[https://github.com/zdk123/SpiecEasi]Updated -
Updated
-
Updated
-

BDS / GeneDER / GeneDER_core
MIT LicenseThis repository contains the scripts that have been developed in the course of the GeneDER project (Biomedical Data Science group - Enrico Glaab Lab).
Updated -
-
Computational modelling and simulation / GeneRegulationAnalysis
GNU Affero General Public License v3.0Gene regulation inference of COVID-19
Updated -

R3 / outreach / papers / gigasom
Creative Commons Attribution 4.0 InternationalGigaSOM.jl: Huge-scale, high-performance flow cytometry clustering in Julia.
Updated -
Environmental Cheminformatics / Gnps Utils
Apache License 2.0Utilities that work with GNPS records.
Updated -
-
Code used for the analysis of the RNA-seq, ATAC-seq and ChIP-seq datasets produced in this study. Original fastq files deposited in https://ega-archive.org/, under the accession number EGAD00001009288.
Updated -
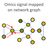
Graph representation learning modelling pipeline exploiting molecular interaction networks of transcriptomics (protein-protein interactions) and metabolomics (metabolite-metabolite interactions) to learn PD-specific fingerprints from the spatial distribution of molecular relationships in an end-to-end fashion. The scripts apply the graph representation learning modelling pipeline on networks of molecular interactions, where transcriptomics and metabolomics data from the PPMI and the LuxPARK cohort, respectively, are projected.
Updated -

Elisa Gomezdelope / GRL_sample_similarity_PD
MIT LicenseGraph representation learning modelling pipeline exploiting sample-similarity networks derived from high-throughput omics profiles to learn PD-specific fingerprints from the spatial distribution of molecular abundance similarities in an end-to-end fashion. The scripts apply the graph representation learning modelling pipeline on sample-similarity networks of transcriptomics and metabolomics data from the PPMI and the LuxPARK cohort, respectively.
Updated -
-
LCSB-BioCore / publications / Hemedan 2023-Boolean modelling of PD
Apache License 2.0Updated -
The sensitivity analysis of IFN1 boolean model is investigated against over expression and knockout mutations. The simulation is performed based on the ranked sensitivity values. Attractors' analysis is also performed to support the main conclusions.
Updated -
-
-
IMP / IMP3
MIT LicenseUpdated